
Немного о распознавании речи с помощью OpenAI Whisper
Автор: Karel WinterskyДолго ли, коротко ли, дошли у меня руки до экспериментов по распознаванию речи с помощью нейросетей. Результаты любопытные (и впечатляющие).
Эксперименты я начал со скрипта batch-speech-to-text, который допилил под себя:
https://github.com/KarelWintersky/ai-speech-to-text
В целом, результаты распознавания меня более чем устроили, хотя результат, разумеется, сильно зависит от модели (конфигурации нейросети).
Картинка для привлечения внимания

О моделях
Движок Whisper предоставляет возможность использовать 5 моделей - от "tiny" (самой простой, но самой быстрой) до "large" (самой эффективной и самой медленной). В readme на библиотеку Whisper довольно подробно расписаны различия моделей, я расскажу о личном опыте:
Во-первых, следует помнить, никакая модель не дает 100% результата. Чем хуже качество исходной записи, чем менее чётко слышна речь - тем хуже будет результат.
Во-вторых, модели "tiny" и "base" можно даже не рассматривать. Не знаю, как они справляются с английской речью, но "Профессор Поцелуй" нервно курит в сторонке:
В следующем году, конечно, когда я вернулся ошаражный пусле этого домой, надо мной долго сержали? Когда я говорю, если я буду по угоду голая. На номер PE, в пыковержнем. Крел вообще, состутый чёткой художественным редактором. Маспосоветла там и там понравилась. Меча, у меня. Меча, куклами. Заболня. Кукленька. Кукленька. Кукленька! Для тебя, отравдел, для того, чтобы все это в принципе, цампец, а ничего не принято, что, а может, проделки. Простученный попался.
Гзабомная, пирька. Кукленька!
и так далее
Модель "small" в принципе, распознает большую часть текста правильно, но иногда рождает странные артефакты вида:
У меня эти каблизаки на должности. Метро роботами, метро куклами. Так, ну, ноги полугорали, клео, ну, конечно, полугорали.
Модель "medium" распознает текст еще лучше, но работает примерно в два раза медленнее, чем small. Результаты еще лучше, но артефакты всё еще встречаются.
Модель "large" работает примерно в 3 раза медленнее модели small, но процент ошибок уже крайне мал. На моем тестовом примере (скрины ниже) модель не распознала Кулибина, выдумала вместо него слово "пуливи". А вот на транскрипции аудиозаписи мастер-класса Олега Дивова (на Росконе 2023) я ошибок практически не вижу (ну, ЭКСМО превратили в "эхмо", АСТ в "аэст" и тому подобное).
В-третьих, мне не удалось задействовать мощности моей видеокарты. Либо видяха слабая, либо я что-то делал не так. За всё отдувался мой AMD Ryzen 5600X процессор:
| Длительность записи | 3:29 | RAM |
| Длительность распознавания | ||
| Tiny | ~0:45 | 520 Mb |
| Base | ~1:06 | 680 Mb |
| Small | ~2:30 | 1.3 Gb |
| Medium | ~5:45 | 3.5 Gb |
| Large | ~8:00 | 6.5 Gb |
Сравнение результатов распознавания


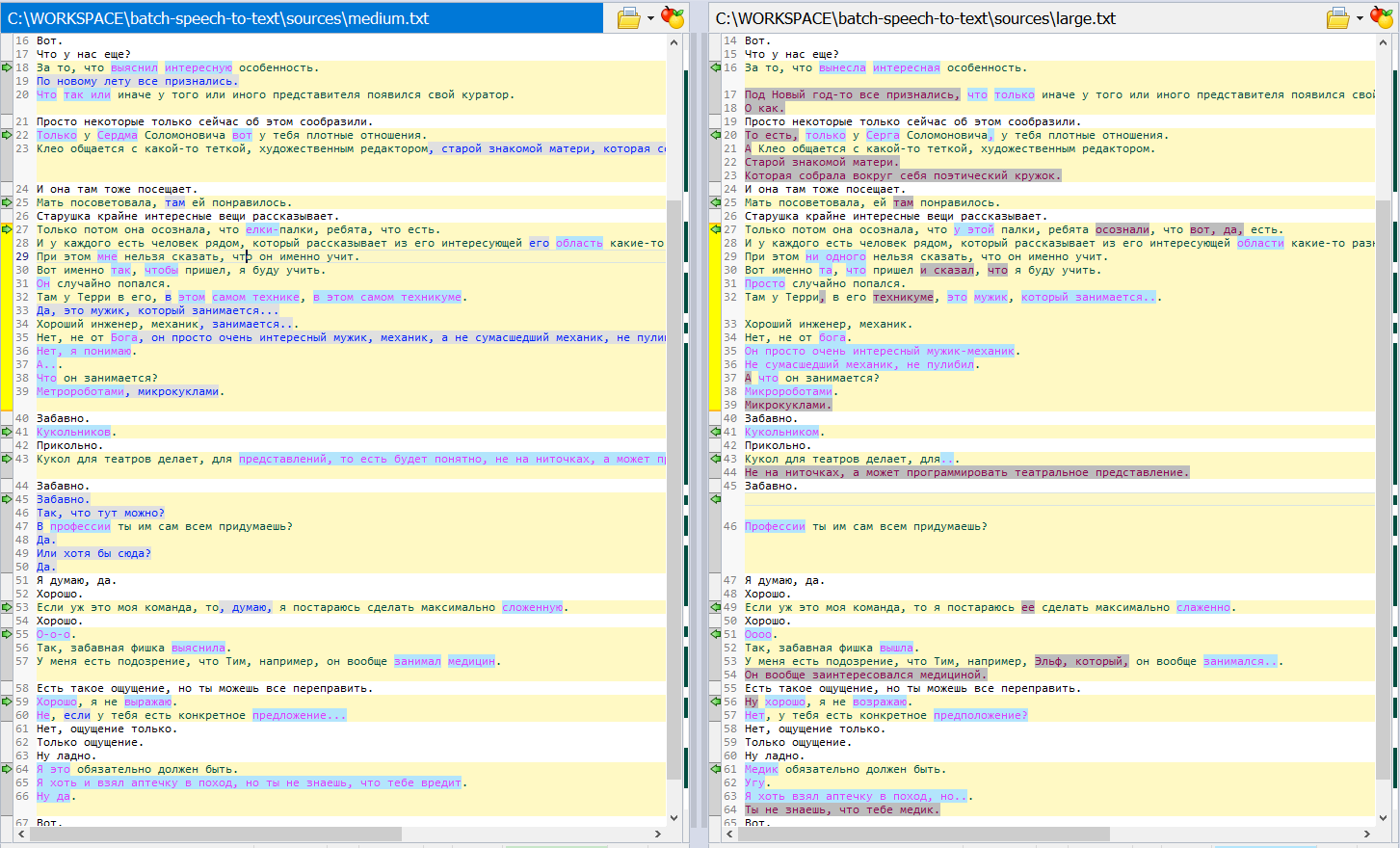
В общем, результаты распознавания ролевой игры на фоне шума электрички, пения птиц, фефектов фикции и уличного шума - мне кажется, вполне приемлемые. Да, если вы хотите получить на выходе полноценный текст - придется слушать и править, но даже такая автоматизация очень сильно облегчает работу.
А вот запись мастер-класса Дивова нейросеть в модели Large распознала почти на "5 с плюсом":
... Я позволю себе рассказать краткую поучительную байку, а может и не краткую, просто для того, чтобы разболтаться, разговориться и вас немножечко размять.
Давным-давно, еще в Советском Союзе, когда в США порядок был, на семинар Всесоюзного Творческого Объединения Молодых Писателей и Фантастов, где разбирались романные рукописи, приехал писатель, назовем его Иванов, для краткости.
И там ты в случае чего, ты это как старый опытный, ты меня подправишь даже, имеешь право.
И там разбирался роман некой, назовем его Лурье, и молодой, талантливый, никому абсолютно неизвестный Иванов встал и разобрал роман Лурье на запчасти, убедительно доказав, что текст абсолютно ничтожен.
Но Иванов совершил одну ошибку.
Точнее, он не мог ее не совершить, потому что он человек такой.
Он разбирал роман Лурье свысока, со свойственным Иванову высокомериям.
Он реально глумился и издевался.
Иванов не учел, он не мог этого знать, хотя, наверное, если бы захотел, мог бы, что Лурье это креатура великого и ужасного льва Вершинина, который уже на тот момент был великой ужасностью.
Лев Иванович не стерпел, что по его протеже ездят грязными гусеницами.
Он взял рукопись Иванова, быстренько ее по диагонали прочел и на следующий день...
Я вот этой серии сожалею, что не присутствовал при сей Виктории хотя бы Мичману, потому что, зная Льва Рынвича, я представляю себе, что это был за спектакль с зачитыванием на разные голоса всех залипух, косяков и свойственных начинающему автору слабостей.
Он разорвал Иванова на 20 маленьких ванов.
Иванов встал и вышел из литературы нахер.
Просто.
Некоторые говорили, у него было такое выражение лица, будто он пошел вешаться, но поскольку он был какой-то человек с улицы, то никто не побежал смотреть, повесится ли он на самом деле.
Приблизительно через 15 лет Иванов в литературу вернулся в качестве автора АЭСТ с романом «Сердце пармы», а затем с романом «Золото бунта».
Его один из критиков провозгласил «золотовалютными резервами русской литературы».
И естественно под это дело, на общем буме, АЭСТ издало собственно ту злосчастную рукопись, которая вот так вот подвижалась.
Поэтому все зависит от вас.
От вашей способности держать удар.
И я почему после этого байку привожу, потому что казалось бы, человек удар не сдержал.
Но он его как-то так в себя очень глубоко пустил, а потом вот так вот выдавил.
И результат был вот такой вот.
Выводы делайте сами.
Для тех, кто хочет повторить моё хождение по граблям
- Ставим Python 3.10+ (https://python.org) и git (https://git-scm.com/)
- Ставим ffmpeg (или прописываем его в path)
- Клонируем репу (git clone https://github.com/KarelWintersky/ai-speech-to-text.git)
- Ставим зависимости (pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git )
- Копируем settings.ini.example в settings.ini и прописываем свои настройки. Там всё прозрачно.
- Копируем распознаваемые файлы (mp3, aac, ogg, wav) в папку исходников
- Запускаем батник.
Это последовательность шагов для жителей Виндоувса, обитатели линукса, во-первых, имеют пайтон искаропки, а во-вторых, смогут прочитать ридми сами и сделать как им привычно.
__________
Такие дела.
P.S. В следующей серии - использование Yandex SpeechKit для той же задачи. Там все немного сложнее и за небольшую денежку.
P.P.S. Важное замечание: если подсунуть нейросети файлы WAV - скорость распознавания будет значительно больше (на 30-40%).