
Гайд по нейросети для чайников. Ставим Stable Diffusion на ПК и учимся им пользоваться
Автор: DunkelheitМне больно видеть, как люди создают кривые нейро поделки в Шедевруме, Кадинском и прочих непонятных сервисах, когда у вас есть бесплатная альтернатива без всяких ограничений.
Поэтому, как видно из названия поста, сегодня речь пойдёт по установке нейросети и обучению. Постараюсь затронуть как можно больше аспектов, но сделать это кратко. Погнали!
ВАЖНО!!!
Для использования нейросети вам потребуется более-менее средний пк.
Самое главное это наличие видеокарты от Nvidia у которой минимум на 4, а лучше 6 ГБ видеопамяти. Если у вас 12 ГБ и больше, то вообще супер.
Насколько помню SD не поддерживает карточки от AMD, но может это ограничение можно как-то обойти. Тут не уверен.
Также желательно наличие SSD куда мы будем устанавливать саму нейронку. Можно установить и на HDD, но лучше всё же отдать предпочтение SSD для быстродействия.
1. Установка
И так, для начала нам потребуется скачать саму нейросеть. Я пользуюсь сборкой Stable Diffusion Automatic, поэтому в гайде все примеры будут показаны на ней.
Сборку я взял из этого видео ещё пару лет назад.
Всё прекрасно работает по сей день, никаких проблем с установкой у меня тоже не было. В чём её плюс? Например в процессе установки у вас сразу установится питон, который необходим для работы нейронки. Так бы вам его пришлось качать и ставить отдельно. Ничего лишнего типо десятков семплеров она тоже устанавливать не будет.
Автор буквально в первых минутах видео описал поэтапно процесс установки, а также принцип работы с нейронкой. Да и у него на канале очень много полезных видео связанных с нейросетями, можете их тоже глянуть.
Дублирую ссылку на скачку из описания под видео https://github.com/serpotapov/stable-diffusion-portable
Предварительно вам потребуется скачать какую-нибудь модель. Для этого мы заходим на этот сайт, желательно регистрируем на нём и включаем в настройках show mature content (поскольку многие модели умеют генерировать NSFW контент, поэтому они будут по дефолту скрыты).
Потом открываем вкладку models (1) и выбираем любую понравившуюся модельку. Можете воспользоваться фильтрами (3) и отсортировать по лайкам, загрузкам и т.д.

На самом сайте модели помечены плашкой checkpoint поверх изображения (2). Приписки справа SD1, XL и Pony (значок лошадки) это грубо говоря тип модели.
SD1 - это более старые модели например Stable Diffusion 1.4 и Stable Diffusion 1.5. Генерируют медленней и в более низком разрешении, зато требует меньше видеопамяти и их очень много. Кроме того, к ним прилагается множество натренированных лор (Lora). Что такое лора объясню чуть ниже.
SD XL - модель поновее. Изначально разрешение генерации у них выше, ровно как и скорость. Но выше и требования к хар-кам вашего ПК. Его вариации Turbo и Lightning работают ещё быстрее, поскольку им нужно меньше шагов и cfg для генерации (что это такое будет расказано позже), однако они ориентированы на небольшое разрешение изображения.
SD Pony - почти тоже самое, что и XL, но они лучше справляются с генерацией всяких фурри и у них довольно хорошая база персонажей и прочего.
UPD!
На данный момент появились также Flux, Illustrious XL и Noob AI
О первом могу сказать, что это крайне прожорливая модель, которая тем не менее наверное одна из лучших по части генерации. А ещё она способна генерировать читаемый текст.
Illustrious XL как и пони появился на базе SDXL. Крайне хорошо справляется с генерацией иллюстраций, особенно в аниме стиле.
Noob AI - модель, созданная китайской компанией Laxhar Lab на базе Illustrious XL. Насколько знаю они использовали базу аниме артов Danbooru для обучения. Всё ещё активно улучшается и показывает крайне неплохие результаты.
Нашёл в интернете табличку с рекомендуемыми требованиями для некоторых моделей. Опять же отталкивайтесь от характеристик вашей видеокарты. У меня например RTX 2060 12 GB этого мне хватает для использования XL и пони моделей.
Illustrious и Noob используют те же параметры, что и SDXL. Flux в зависимости от версии требует от 8 до 24 ГБ. Конечно умельцы придумали как запустить его при наличии совсем небольшого объёма VRAM, но тогда вы СИЛЬНО потеряете в скорости генерации и качестве изображения.

А теперь кратко: что же такое Lora?
Обычная модель весит в районе 2-8 гб, а лора это сжатая модель. Они обучаются для конкретных вещей. Например вы хотите сгенерировать знаменитость или персонажа из игры, или вам хочется чтобы ваша картинка была в стиле какого-то конкретного художника, или скажем вы хотите сгенерировать гладиатора, но ваша модель ни в какую не хочет создавать ему гладиаторский шлем. Тогда вам на помощь приходят лоры. Весят они в районе 20-250 мб и устанавливаются в отдельную папку.
Так же существует Lycoris и Dora.
Первое это устаревший предшественник лор, а второе более новый, но если честно не знаю его особенностей, ибо их мало и я ещё не пользовался ими  . Поясняю это всё за тем, чтобы вы не путались на сайте в дальнейшем.
. Поясняю это всё за тем, чтобы вы не путались на сайте в дальнейшем.
Теперь, предположим вы скачали модель, установили нейросеть и запустили. Перейдём к следующему пункту.
2. Интерфейс
Тут я постараюсь разбить инфу на пару пунктов, чтобы вам было удобнее читать.
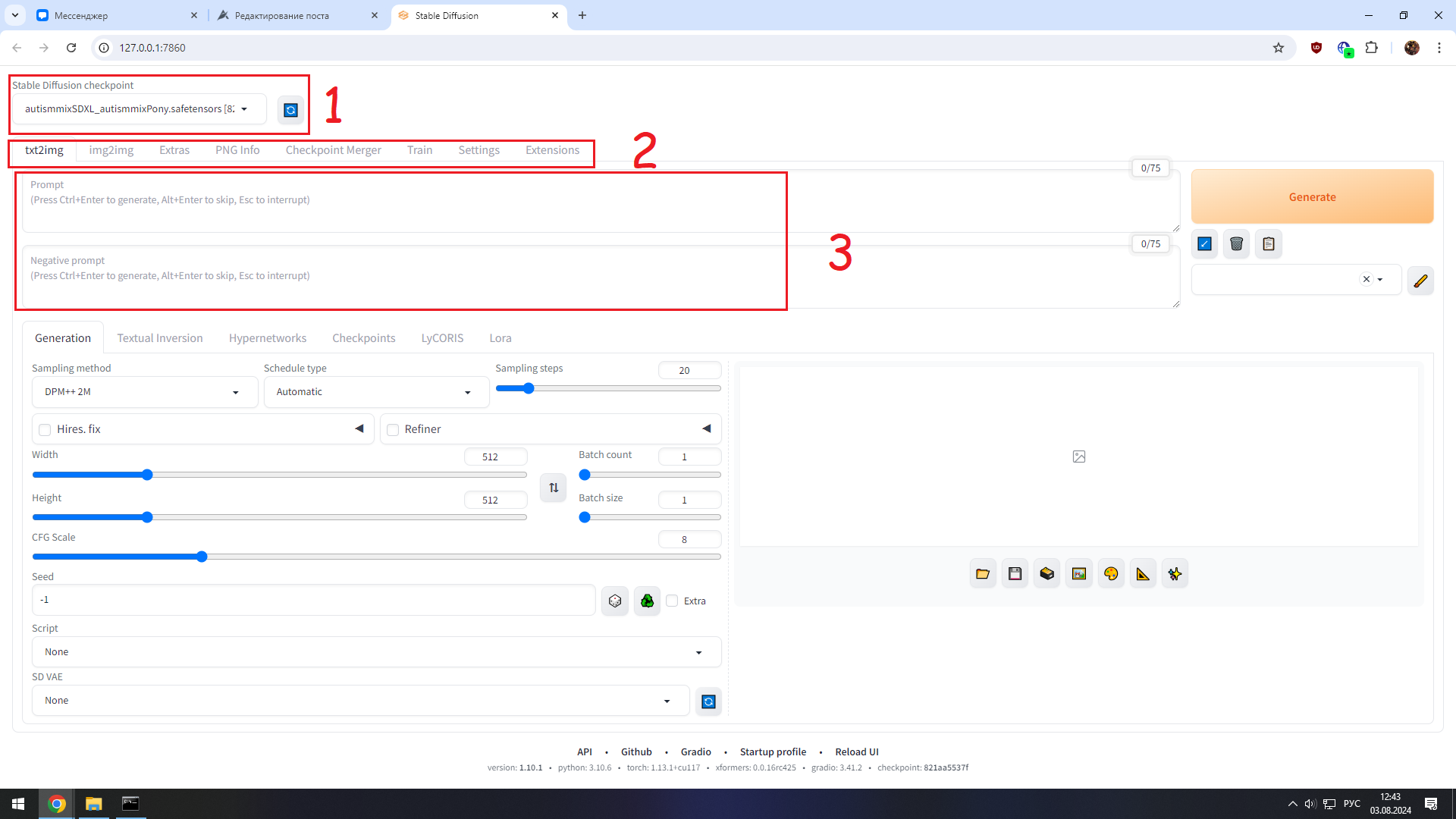
1) Здесь мы меняем наши чекпоинты (модельки).
2) По сути нас тут интересует только 2 вещи txt2img (текст в изображение) - генерация изображения по описанию и img2img (генерация изображения на основе другого изображения)
3) Окошко с промтом - описываем, что хотите сгенерировать вверху и что не хотите видеть на своей картинке внизу.

1) Здесь нас интересует только параметры генерации.
3) Здесь будет показана сгенерированная картинка.
4) Полезные кнопочки. Можно навестись и почитать, что они делают. Например
Папка - открыть директорию куда сохраняются все наши картинки.
Дискетка - сохранить картинку (если у вас отключено автоматическое сохранение)
Картина - перенести изображение и выставленные параметры генерации в раздел img2img.
Палитра - тоже самое, только в раздел инпента (редактирования изображения)
2) Окошко с параметрами генерации (на скрине конкретно показано для txt2img, другие разделы будут чуть отличаться)
Семплеры и шедулеры. Изначально с установкой нейросети у вас они по идее будут не скачаны, чтобы не забивать память. Вы скачаете лишь те, которые выберете в процессе генерации.
Но по сути из семплеров вы всегда будете пользоваться DPM ++ и Euler и их вариациями. А из шедулеров Automatic либо Karras.
Sampling steps - количество шагов генерации. Оптимально выставлять где-то 20-30. Можно поставить 50-100 если делаете картинку в очень большом разрешении, но это лучше делать уже при апскейле.
Hires fix - если поставите галочку он повысит разрешение вашей картинки при генерации. Но делать этого я не рекомендую. В самом конце поста объясню почему.
Refiner - установка галочки позволит выбрать 2 модель при генерации. Как по мне не особо полезная функция, ибо очень сильно замедляет генерацию, поскольку нейронка выгружает уже загруженную модель из оперативки и начинает грузить туда вторую.
Width - ширина картинки, которую мы будем генерировать
Height - высота
Лучше не выставлять эти 2 параметра сильно высокими иначе ваш пк взорвётся на пк будет большая нагрузка, что приведёт к лагам. В одной статье находил такие рекомендуемые параметры для SDXL моделей.

CFG Scale или Guidance в других вариантах - не знаю как объяснить. Грубо говоря это сила, с которой модель будет следовать промту. Сильно выкручивать не надо иначе всё изображение будет в артефактах, низким делать тоже не следует.
Batch count - количество пакетов (генераций)
Batch size - количество изображений, созданных за одну генерацию
Т.е. если вы поставите Batch size 4, а Batch count 2. Нейронка сгенерирует вам одновременно 4 картинки за первую генерацию и следом проведёт вторую генерацию, создав ещё 4 картинки.
Seed - грубо говоря ключ нашего изображения. Изначально он стоит -1, в таком случае изображение каждый раз будет генерироваться случайным.
Поле скрипт нам не нужно, а вот о поле VAE расскажу чуть подробнее (хотя оно у вас будет спрятано изначально в настройках самой нейронки).
Для начала определение из гугла
Вариационные автокодировщики (VAE) — это архитектура искусственной нейронной сети для генерации новых данных. Они похожи на обычные автокодировщики, которые состоят из кодировщика и декодировщика. Кодер берет входные данные и сжимает их в скрытое представление. Тем временем декодер пытается восстановить исходные данные из этого сжатого представления.
Если говорить проще, они помогают улучшить качество нашей картинки. Для старых моделей например SD 1.5 лучше всего использовать vae-ft-mse-840000-ema-pruned.ckpt
Для XL и Pony нам потребуется SDXL Vae.
Взять её можно например здесь
Справа раскрываем спойлер и качаем 2 файл

Ваешки мы закидываем по следующему пути. У вас он может чуть отличаться.
C:\stable-difussion\models\VAE
И включаем их в настройках здесь.

ВАЖНО!!!
В каких-то моделях уже может быть вшита ваешка. Обычно на сайте в версии модели стоит пометка baked vae или without VAE (если её нет).
3. Генерация
Скорее всего вы уже задались вопросом, а какие параметры генерации вам лучше всего установить?
Чаще всего на civitai (сайт где мы качаем модельки и прочие полезности для нашей нейронки) в описании моделей авторы указывают рекомендуемые параметры для генерации. Какое ставить разрешение, семплеры, количество шагов, cfg скейл и прочее.
Например в описании к этой модели


Теги в начале промта score_9, score_8_up, score_7_up, BREAK актуальны только для пони моделей. Если вы ставили SD или SDXL модель вам их добавлять не требуется.
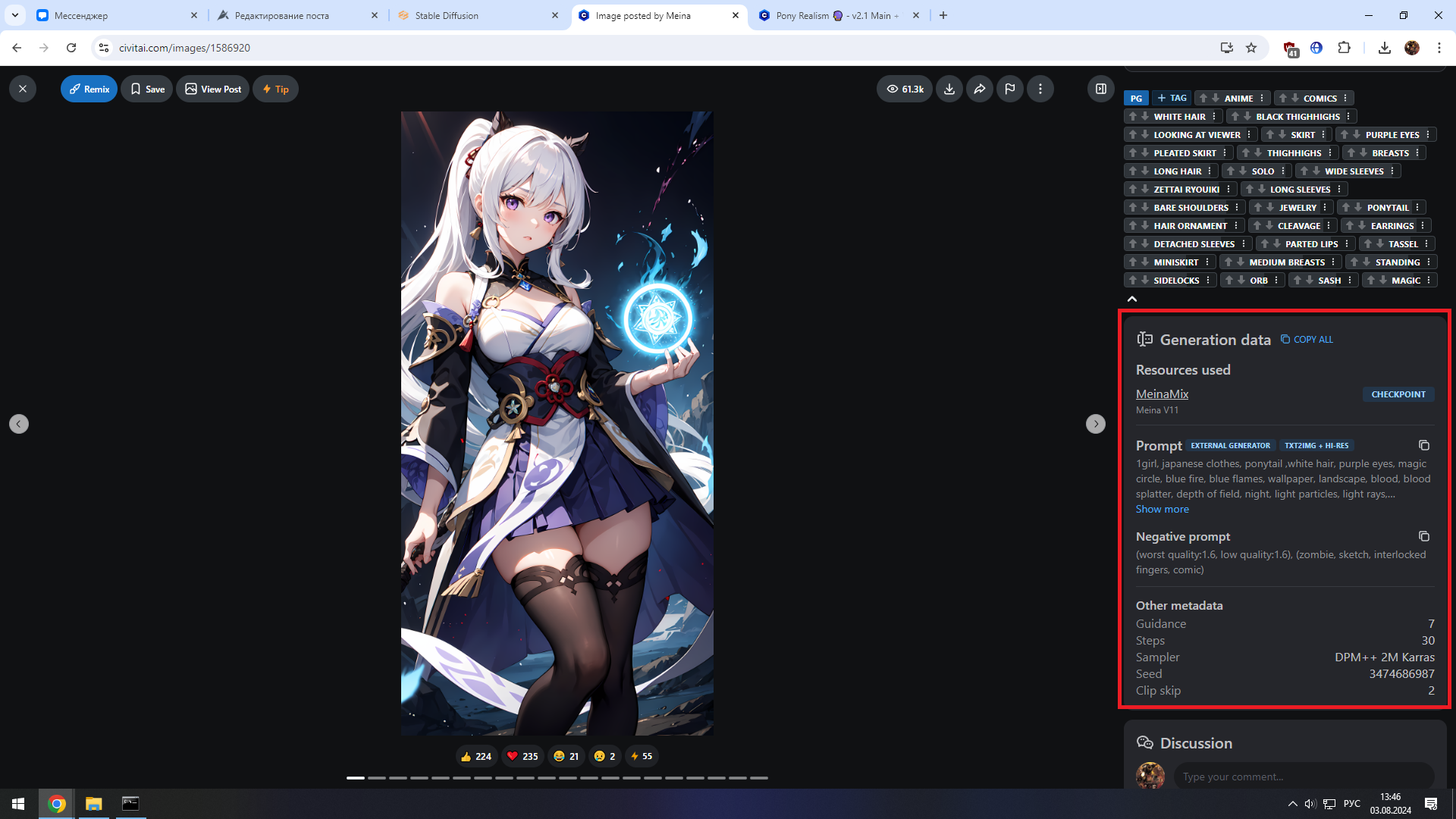
Альтернативный вариант - скоммуниздить параметры генерации у кого-нибудь другого. Все изображения на civitai открываются и в 90 процентах случаев у них будут показаны все параметры задействованные при генерации. От моделей и лор, до промта, разрешения и т.д. Поэтому можете ткнуть на любое изображение вверху на странице модели и глянуть что использовал её автор, либо пролистать чуть ниже и посмотреть какие параметры выставляли пользователи.
Пойдём дальше.
4. Редактирование
Предположим вы немного поигрались с нейронкой, создали более-менее приемлемое изображение, но как его улучшить?
Для начала избавимся от косяков с помощью опции инпеинта. Вверху переходим в раздел img2img, а потом чуть ниже жмём на вкладку inpant (1). Либо более предпочтительный вариант сразу под картинкой жмём на иконку палитры, нас туда перекинет автоматически и скопирует все наши параметры для генерации.

Я выделил только самое главное.
inpant masked - перегенерирует всё, что вы выделите карандашиком в окошке ниже.
inpant not masked - наоборот, всё что мы не выделили.
masked content трогать не надо. Оставляйте его либо fill либо original
inpaint area - грубо говоря, что подвергнется генерации. Вся картинка целиком (whole picture) или только выделенная вами область (only masked).
Параметр Only masked padding, pixels я никогда не трогаю, как и Mask Blur (размытие маски). Последнее нам потребуется изменять только для софт инпента.
Soft inpainting - добавляет контент, который смешивается с оригинальным. Не стану подробно расписывать, и так уже пост вышел сильно большим. Рекомендую глянуть эту статью, тут всё доходчиво и наглядно показали.
Ну и в самом низу, под параметрами генерации у нас есть такая шутка, как Denoising strength
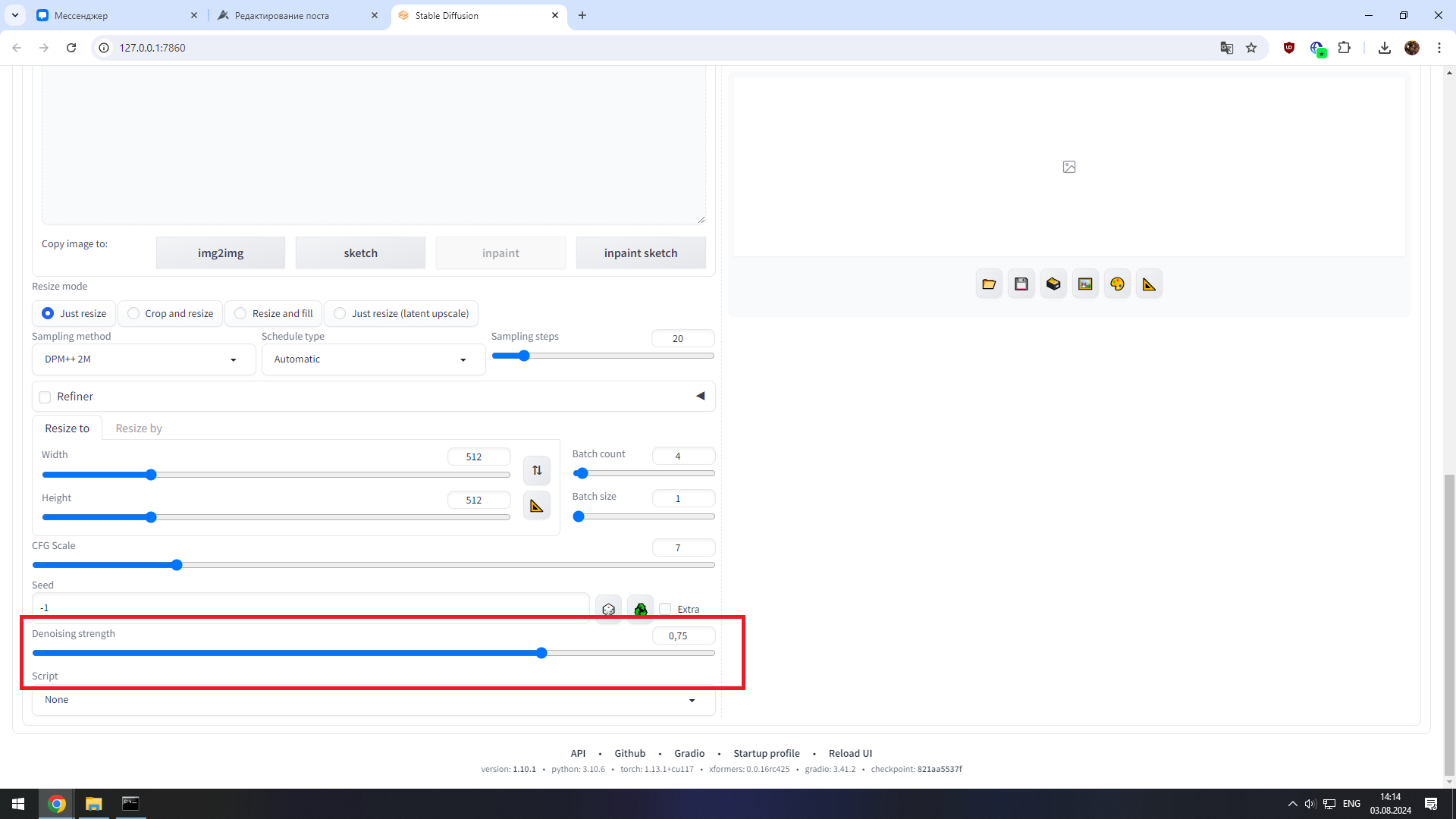
Этот параметр прежде всего используется в разделе img2img. Он влияет на отличие картинки на выходе от исходной. Чем он больше - тем сильнее новая картинка будет отличаться от изначального варианта.
В случае с инпеинтом он будет затрагивать только выделенную область.
Редактируйте поэтапно. Например у вашего персонажа криво сгенерировалась одна рука и лицо. Сначала выделяете лицо и генерируете его пока не устроит, потом стираете маску и выделяете руку.
Обычно, если мне требуется поправить какую-то деталь, я могу вообще не трогать изначальный промт. Просто выделяю нужную область на картинке, ставлю галочку в поле soft inpaint и only masked, а параметр denoising strenght в зависимости от модели ставлю на значение 0.5-0.65 либо 0.75-0.95. Если у вас что-то не получается обращайтесь, я постараюсь помочь разобраться.
И вот, когда мы поправили все косяки, можем перейти к заключительному пункту.
5. Повышаем качество изображения.
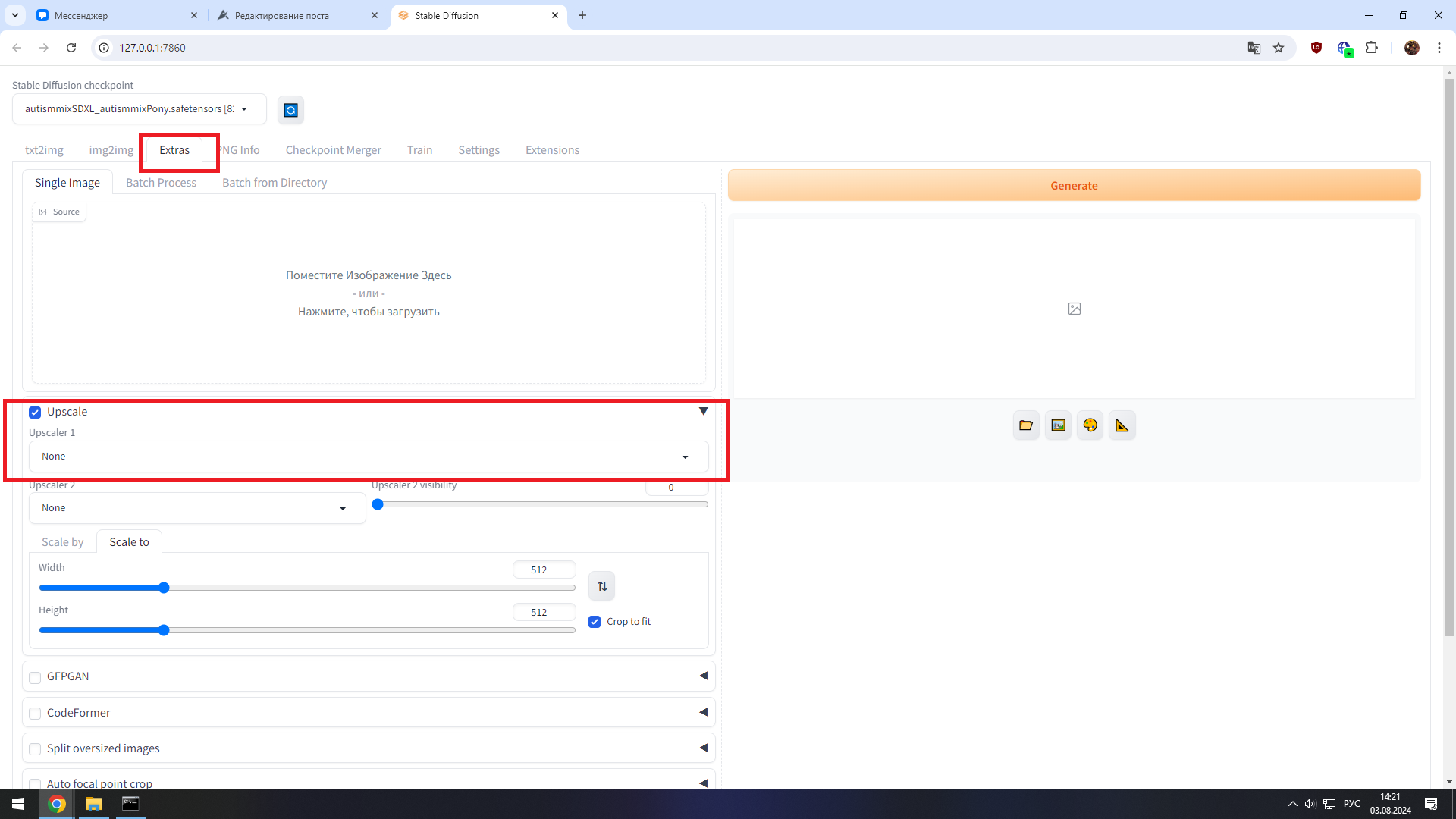
Для этого мы напрямую переходим во вкладку "Экстра" и загружаем наше изображение, либо делаем это через иконку с треугольником. Затем внизу жмём галочку напротив upscale и в 1 же поле выбираем ESRGAN либо R-ESRGAN (это базовые апскейлеры, которые у нас есть изначально. Можете скачать и другие в интернете, например Remacri).
Затем ниже выбираем либо scale by там нам придётся выбрать во сколько раз мы хотим увеличить качество исходного изображения, либо scale to и прописываем конкретные значения ширины и высоты.
Готово! Вы восхитительны!
И напоследок: почему не стоит трогать параметр Hires fix?
Поскольку нейронка с 1 раза обычного ничего путного не выдаёт, нам важна скорость генерации. А для этого мы жертвуем разрешением и ставим его не слишком высоким. Например 1024 на 1344.
Если мы поставим хайрез фикс мы будем генерировать картинки с большим разрешением, но соответственно потеряем в скорости. Ну и от возможных косяков не избавимся. Стоит ли ждать пару минут и получить на выходе картинку, где будут кривые руки или глаза у персонажа перекошенные?
Вот поэтому мы сначала генерируем приемлемую картинку в низком разрешении, зачем это редачим через инпеинт и наконец апскейлим до хорошего разрешения.
На этом всё, надеюсь, кому-нибудь этот гайд окажется полезен.