
Наглядно о том, как плохо распознают детекторы ИИ
Автор: Антон ШахВсем доброго времени суток...
Знаю, всем надоела на самом деле вся эта тема с ловлей ИИ, мне тоже, но мы живём в период нейросалемского движения, тут уж ничего не поделаешь. Однако, мне стало интересно проверить самому то, сколь же хорошо определяют всяческие там модели тексты. Особенно, когда он точно был написан человеком. Понимаю, мой эксперимент предельно далёк от полноценного исследования да и делать проверку всего одним абзацем — звучит «гениально». Но всё же результат вышел весьма и весьма занятный.
Вчера по бложикам вспоминали Горыныча, но пока тот лежит, так что на сцену вышел детектор, обновлённый, от Яндекса. Дабы вы сами могли тоже попробовать, вдруг вам даже на мои результаты даст иные цифры, прилагаю ссылочку.
https://yandex.ru/lab/neurodetector
Что именно я скормил ему? Вот абзац без редактуры и перечитывания, сырой поток из головы.
До начала времён не было ничего кроме бесконечной тишины. Не той, что покоится в центре бури, нет, той что была и будет за гранью первого звука. Густая и насыщенная, словно наваристая похлёбка самого мироздания. И именно в ней отражалось кругами по поверхности сердцебиение древнего, могучего, бывшего ещё до самого понятия Ничто. Дремавшего под слоями камня.

Можете нажимать на скриншоты для просмотра в большем разрешении. А так, крайне низкий процент да и тот обусловлен лишь тем, что предложения сложные и набором свойств, что является нормой для подачи в духе, сказания или легенды, но попадает при этом под шаблоны немного.
Ладно, хорошо. считается, почему-то, что результат до 25 процентов - человек. А дальше уже смесь и полностью ИИ. Ок, теперь дадим прошедший редактуру текст. Небольшое причёсывание, не более того.
До начала времён не было ничего, кроме бесконечной тишины. Не той, что покоится в центре бури, нет — той, что была и будет за гранью первого звука. Густая и насыщенная, словно наваристая похлёбка самого мироздания. И именно в ней отражалось кругами по поверхности сердцебиение древнего, могучего, бывшего ещё до самого понятия Ничто. Дремавшего под слоями камня.
Запятая перед оборотом с «кроме» со значением исключения. Тире для выделения уточняющей конструкции, запятая перед придаточным. В общем, элементарнейшее соблюдение правил русского языка и не более того. Каков результат?
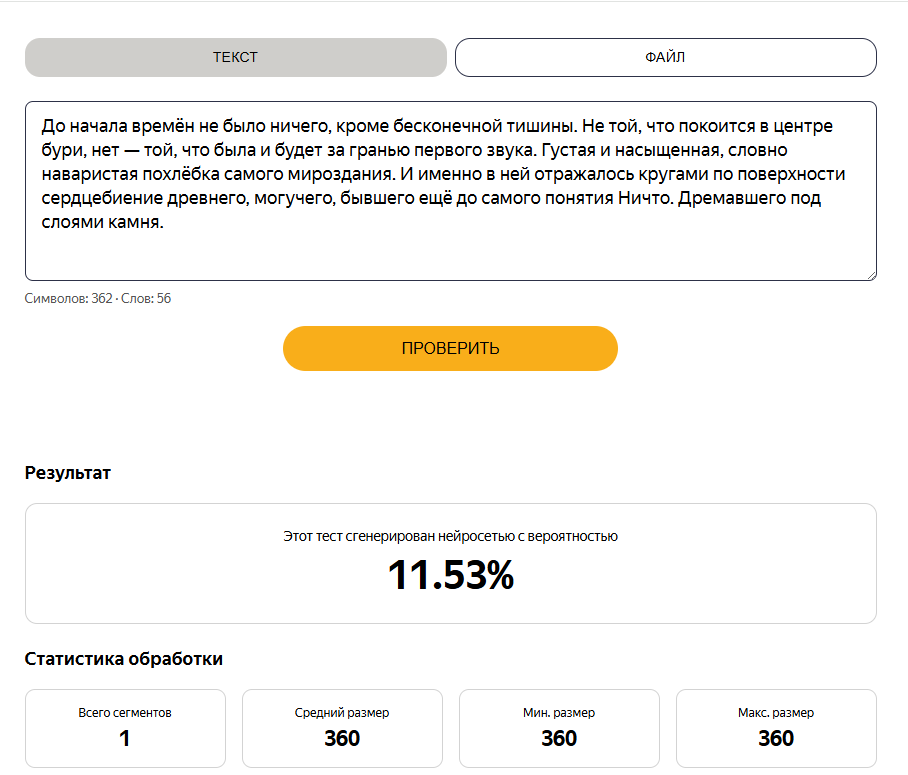
Эвона как... процентики заметно подросли. Но почему? Ответ тут в том, но это чисто предположение, что текст стал слишком правильным. Может, правда, всё ещё и есть ошибки на самом деле, я не гуру русского языка, но держите просто в голове этот результат, ибо дальше будет интереснее.
Я начинаю вносить совсем небольшие изменения.
До начала времён не было ничего, кроме бесконечной тишины. Не той, что покоится в центре бури, а той, что была и будет за гранью первого звука. Густая и насыщенная, словно наваристая похлёбка самого мироздания. И именно в ней отражалось кругами по поверхности сердцебиение древнего, могучего, бывшего ещё до самого понятия Ничто. Дремавшего под слоями камня.
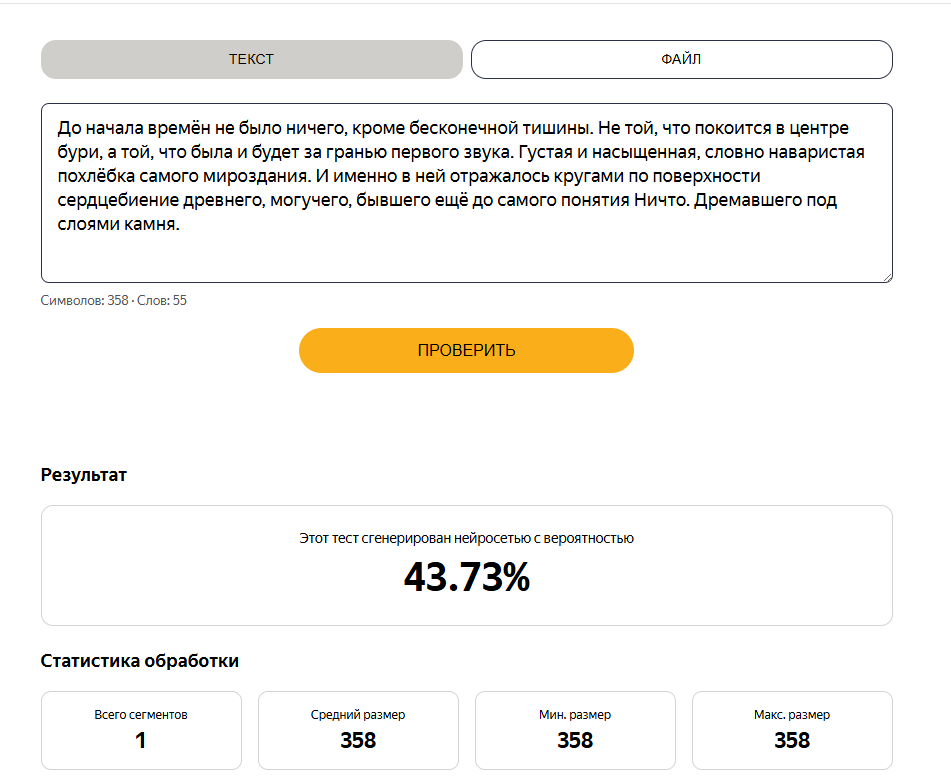
Что? Да как так-то? Стоило капельку изменить предложение, сделать в нём "а той" и всё, процентовка уже уровня совместного написания. При этом, очевидно, хватает же людей, что пишут вот так, но подождите, ибо дальше будет ещё занимательнее.
До начала времён не было ничего, кроме бесконечной тишины. Не той, что покоится в центре бури, а той, что была и будет за гранью первого звука. Густая и насыщенная, словно наваристая похлёбка самого мироздания. И именно в ней отражалось кругами по поверхности сердцебиение кого-то древнего, могучего, бывшего ещё до самого понятия Ничто. Дремавшего под слоями камня.
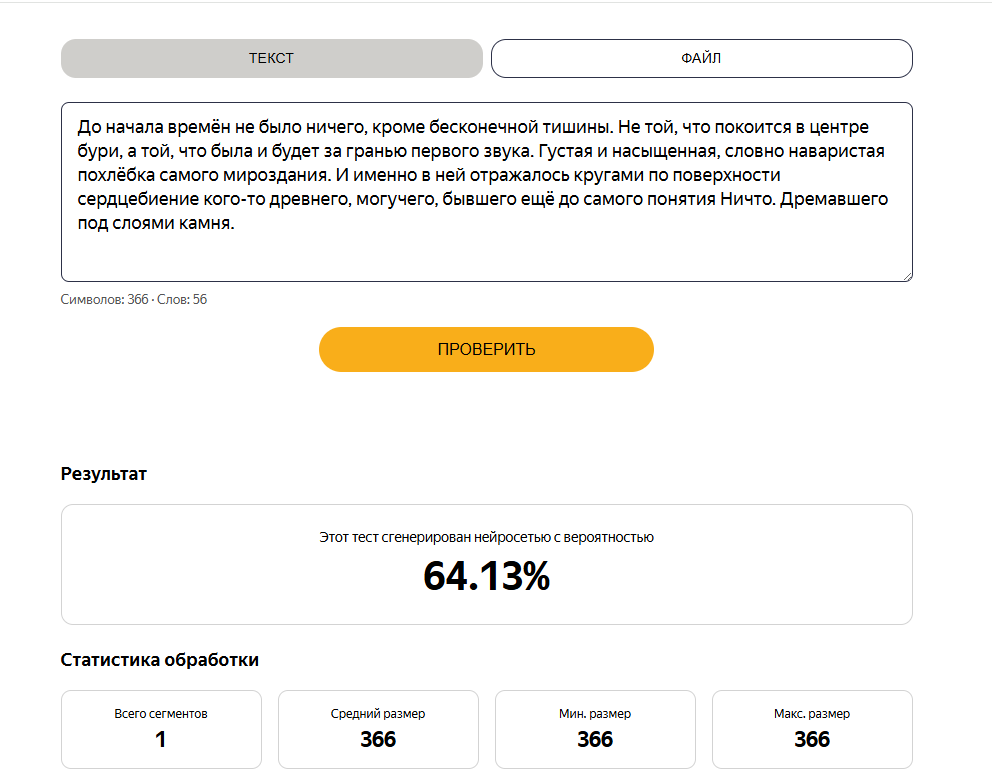
Ага, добавление "кого-то" сразу же сделало прибавку в двадцать процентов грубо говоря. Миленько, правда? Поехали, теперь добавление слова снизит процент, что тоже интересно.
До начала времён не было ничего, кроме бесконечной тишины. Не той, что покоится в центре бури, а той, что была и будет за гранью первого звука. Густая и насыщенная, словно наваристая похлёбка самого мироздания. И именно в ней отражалось кругами по поверхности сердцебиение кого-то древнего, истинно могучего, бывшего ещё до самого понятия Ничто. Дремавшего под слоями камня.

Ага, ромфант с имтинными парами на 10 процентов человечнее, ведь слово "истинно" настолько и очеловечило про мнению детектора вероятность.
Дальше мне стало лень играть с буковками, но есть подозрение, что можно и под сотку вывести процентики, просто запятой в каком-нибудь месте или дополнительным словом. И да, я прекрасно понимаю, повторюсь, что проверка на всего одном абзаце выглядит сюром, но просто подумайте теперь о том, что и в большом тексте каждое слово может порождать подобные приколы. К тому же, мы понятия не имеем какие именно базы данных были использованы для обучения детектора, а это тоже важно, ведь любое отхождение уже может засчитать за галлюцинацию от ИИ.
Так что, не майтесь и не занимайтесь дуростью, а пишите проды, так как вы умеете. И да, возражения о том, что этот детектор фигня и иди проверяй вон в том не принимаю. Потому что и без того хватает примеров с детектами на классику и прочих приколов.
Объективно, единственный способ детекторам сто процентов выявлять, это обязать в текст каким-то образом вшивать цифровой код генерации. В музыке подобное есть, у нейромузыки уже приколы с выкладкой на площадки с заработком, например, но в музыку и проще вшить на неслышимые человеку частоты. Про частоты не точно, но это самый вероятный вариант принципа работы. Особенно, учитывая каким образом обходят, до поры до времени. Кхем, так вот, а можно ли также с текстом? Не знаю, но думаю нет и причин тому много.
Прочие же все эти супер детекторы в серьёз не воспринимал и продолжу не воспринимать.
И да, не претендую на истину в последней инстанции, чисто моё мнение и просто поделился на надоевшую тему. Естественно, ярые фанатики детекторов продолжат бить в грудь и горлопанить о том, что нет, вот ИИ определило ИИ.
ИИ определило ИИ...
А что если мы сами тоже ИИ? Я и вы - симулякр?.. 