
Ещё раз про детекторы и про мой аудитор
Автор: Олег КолокольниковТретьего дня я представил свой аудитор стиля текста.
https://olegkolokolnikov.github.io/style-auditor/
https://auditor-f-olegkolokolnikov.amvera.io/
Я благодарен всем комментариям и замечаниям, благодаря им я там многое улучшил. Большинство комментариев было связано с тем, как понимать результаты и зачем это нужно. И это абсолютно логично, так как необходимо знать, что и как проверяется во всех этих программах.
Это — аудит, который может быть нужен, чтобы проверить собственную работу на тонкие моменты и носит исключительно рекомендательный характер.
Почему я за это взялся:
Моя главная претензия к детектору от яндекса в том, что это магическая чёрная коробочка.
Да, есть шанс, что он часто показывает правду, но крики о том, что «какие ещё нужны доказательства нейрослопности» — беспочвенны. Не существует магического способа определить нейротекст, есть только совокупность общих паттернов, которые сами по себе ничего не означают, кроме того, что текст вызывает подозрения.
Тем более, нельзя полагаться на алгоритмы, если мы не знаем, что это за алгоритмы и как они работают. Даже если они «по ощущениям» показывают правду.
Теперь о том, что же получилось у меня. Я прогнал через свой аудитор стиля «Фиаско» Станислава Лема:
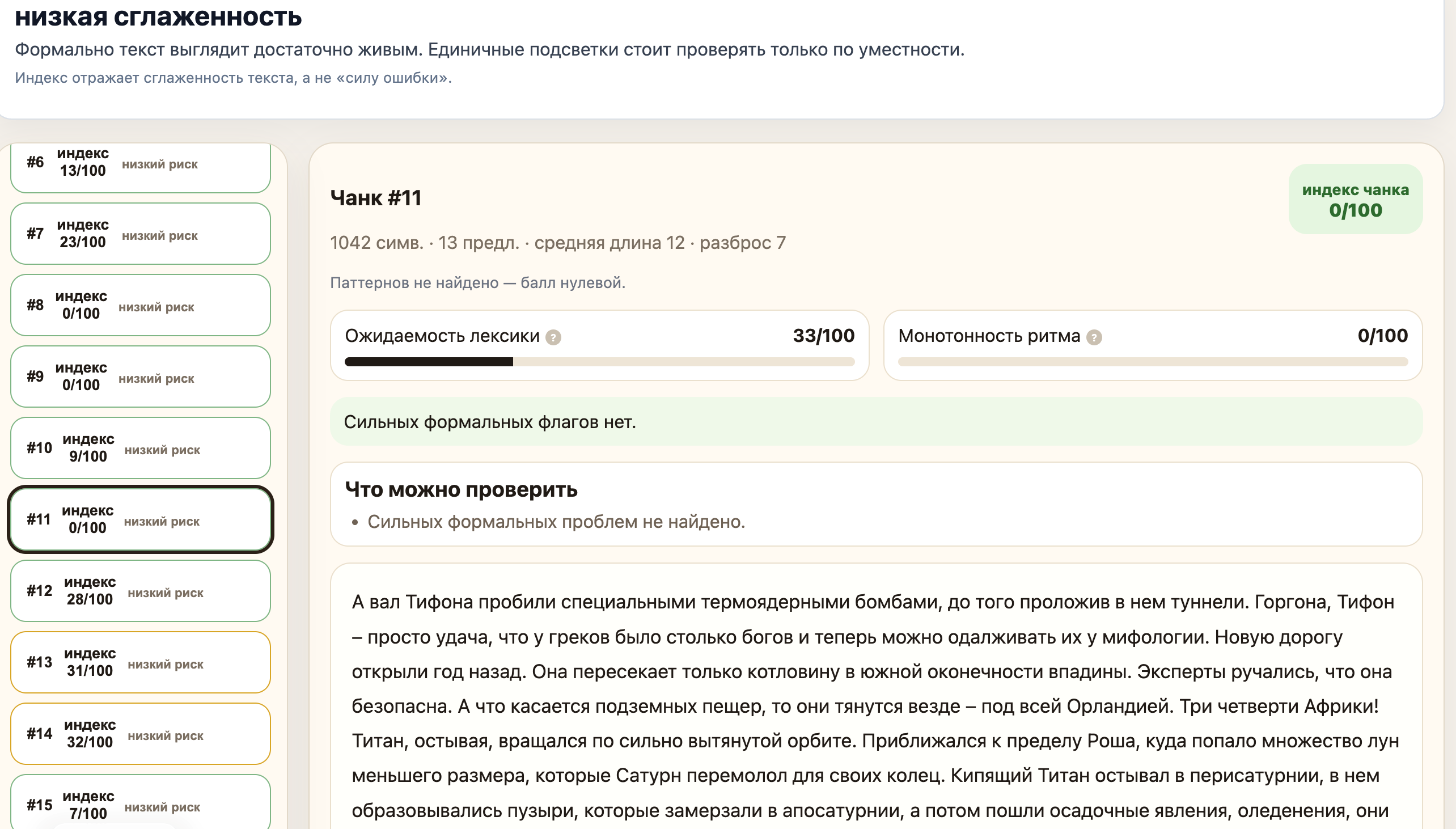
Везде «низкий риск»! Текст — однозначно идеален или близок к идеалу.
А теперь мой самый сомнительный «Праздник урожая», который люто бешено ненавидит яндекс:

Как можно заметить, всё честно, мой текст и вправду косячный.
НО: видно абсолютно все «сомнительные» места, которые могут вызвать вопросы.
Повторюсь: это — не нейродетектор, это — аудит, который может быть нужен, чтобы проверить собственную работу на тонкие моменты и он носит исключительно рекомендательный характер.
Все параметры, которые заложены в аудитор:
Индекс чанка
Число от 0 до 100. Складывается из штрафных баллов за каждый найденный паттерн — чем серьёзнее паттерн, тем больше очков он даёт (от 5 до 15). Метрики сглаженности (ритм, лексика) добавляют баллы сверху. Несколько паттернов на одном участке перекрываются и окрашиваются красным — это тоже усиливает счёт. Итоговый балл не суммируется по чанкам: каждый оценивается независимо.
Цвета подсветки
- низкий — слабый сигнал, одиночный случай не критичен
- средний — стоит обратить внимание при накоплении
- высокий — характерный паттерн, рекомендуется правка
Паттерны
Пункт 1
«Это не… Это…» — драматический контраст. Одиночный случай не страшен, опасно накопление.
Пункт 2
Серия коротких фраз подряд — три и более предложения длиной до 4 слов.
Пункт 3
Тройное перечисление. Нормальный приём, но при избытке заметен.
Пункт 4
Псевдоафоризм — обобщающая фраза в конце абзаца.
Пункт 5
Эмоция-ярлык — абстрактное чувство в коротком отдельном предложении.
Пункт 6
«Не потому что… а потому что…» — объяснительная связка. Шаблонна при повторе.
Пункт 7
Зеркальное предложение — соседние фразы с перестановкой похожих слов.
Пункт 8
«Как будто / словно» — сравнения. В хорроре норма, но частый повтор заметен.
Пункт 9
Повтор начала предложений — соседние предложения начинаются с одного слова.
Пункт 11
Два прилагательных перед существительным через запятую.
Пункт 12
Тире вне диалога — частые тире в авторской речи. Диалоговые тире игнорируются.
Пункт 14
Гипербола — громкое усиление. Само по себе нормально, при избытке создаёт пафос.
Пункт 15
«Не просто… а…» — усилительная конструкция. Шаблонна при накоплении.
Пункт 16
Абзац-крючок — абзац начинается одиночным словом.
Пункт 17
Жирный текст внутри художественного фрагмента.
Пункт 18
Запах — сенсорное описание через обоняние. Проблемно, если встречается в каждой сцене.
Пункт 19
Помпезное сравнение — тёмная образность. Работает дозированно.
Пункт 20
«Нечто большее, чем…» — шаблонный оборот.
Метрики сглаженностиS1 — Монотонный ритм
Предложения в чанке близки по длине — стандартное отклонение длин меньше 3 слов. ИИ генерирует предложения ровными «волнами» (12–15 слов, снова 12–15…), живой автор неосознанно чередует короткие и длинные. Подсвечивается весь фрагмент целиком.
S2 — Общая оценочная лексика
Много размытых прилагательных (красивый, странный, тёмный и т.п.).
S3 — Предсказуемость лексики
Высокая доля частотных, абстрактных или взаимозаменяемых слов. Модель считает четыре группы: частотные служебные слова («и», «в», «не»), абстрактные эмоции («страх», «тревога», «боль»), общие глаголы восприятия («понял», «почувствовал», «увидел») и плавные связки («словно», «будто», «вдруг»).
Проект этот я делаю для себя, используя те самые нейросети, идея в самообучении и вообще я ж программист, надо пользоваться этим :) Но если кому-то будет интересно, то ближайшие пару недель он ещё побудет в публичном доступе.
Исходный код тут, проект можно запускать локально (нужны базовые знания явы и реакта), без этих всяких интернетов:
https://github.com/OlegKolokolnikov/style-auditor
Любые замечания и предложения будут рассмотрены с благодарностью 
ЗЫ: тексты никуда не сохраняются, так как там нет базы данных. Нет даже кэширования, то есть сто раз посланный текст будет проверен всю сотню раз. Но проект сырой, могут быть сюрпризы (но пока не было).