
про "найти похожую книгу" и теги
Автор: Виктор ВайерПредыстория тут. Щас копаюсь в имеющемся наборе данных (описания книг около 40тыс). В принципе, простая нейросеть-автокодирощик, тупо обученная на тегах, умеет показывать наиболее похожие по тегам книги.
Само по себе это не идеально, поскольку понятно что любое описание не соответствует содержанию. Но в принципе этим уже можно искать "чо почитать" чуть более интересным образом нежели тупым ковырянием в поиске среди топчиковых огрызков серий без начала конца и смысла.
Но в тегах есть две коварные проблемы, о которых не задумываются авторы. Это "шум" - шум это бессмысленные теги, и теги-мусор.
Самые популярные теги:

У нас как бы есть жанры "фентези", "фантастика" - соотвественно смыслово нагрузки такие теги не несут. Зачем нужен тег "рассказ" - я затрудняюсь предположить. Тег "приключения" - ээ? Ну то есть понятно, что на психологической драме его не будет, наверное. Но из-за его огромной популярности (в принципе большинство самиздатовских книг про приключения же) он теряет значимость.
Если что на АТ ~150 000 книг, и среди них очень много (67 000) рассказов, порой вовсе без тегов.
С другой стороны популярности тегов есть т.н. "хвост" - множество тегов используемых по десятку раз и менее. Посчитать их мне не представляется возможным. Но например на выборке из 40тыс книг, у нас более 6000 тегов, встречающихся хотя бы по два раза.
upd. Пример распределения тегов, отсортированных по частоте (в выборке из 40тыс книг). Вертикальная шкала "частота" - логарифмическая:
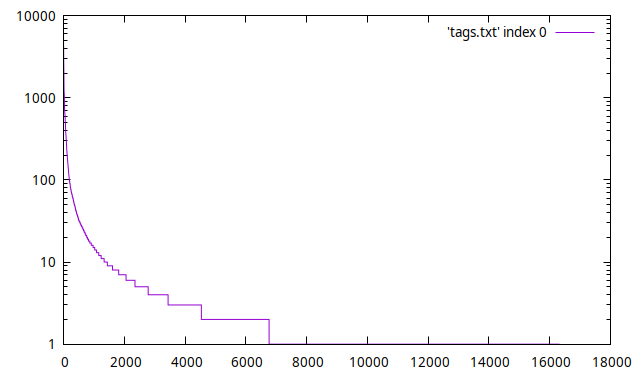
При том, для задачи поиска "похожих книг" (похожих по описанию, напоминаю) редкие теги наиболее ценны, так как они могут нести более характерные признаки, чем какой-нибудь тег "приключения". Ну для примера тег "биопанк" (160 упоминаний) даёт более характерные признаки, чем "приключения".
Однако "хвост" списка тегов сильно замусорен - там куча тегов ради шутки, тегов вида "фентези" (на деле этот тег конечно не в хвосте, но зато типичный пример) и прочего.
В идеале при реализации поиска "похожих" книг все мусорные и бессмысленные теги надо как-то обработать. "Фентези" приравнять к "фэнтези", мусор выкинуть. Ну и как-то определить характерность тега.
Проблема в том, что компьютеру максимум что доступно это определить характерность и то приблизительно - для обучения нейросети я взял log₁₀(наибольшая_встречаемость - встречаемость_тега) - это как-то даёт более-менее с виду пристойные результаты. (upd. судя по последним тестам - это не работает, так как "любовь" - достаточно характерный тег, но и очень популярный)
Потом придётся городить алгоритм поиска похожих тегов и т.п. - так как тегов слишком много и если скармливать нейросети их все, то обучаться это дело будет слишком долго (и не факт что успешно). Причём для подобных задач нейросети то придётся обучаться регулярно (чтобы понимать новые книги, теги и т.п.) и не на видеокарте (для сервера это слишком дорогое удовольствие).
В общем это я всё к тому, что лучше всего заранее выставлять теги грамотно и вдумчиво.
Но это нереально - ни один намеренно пишущий "фентези" добровольно не согласится поставить более популярный тег "фэнтези", а значит всё бессмысленно.