
Нейросети, писательство и секретный соус
Автор: John DoeВступление
Данный пост является довольно запоздалой реакцией на пост другого пользователя платформы AT. А именно на пост «Записки с писательского фронта: откровения, решения и нейросети в котле» пользователя Никиты Сёмина.
Если кратко, то в этом блоге человек пишет, что в своей работе писателя он использует нейросети, уточняя что начал работать с ними начиная с GPT 3.5* (релиз – 15 марта 2022 года, размер контекстного окна (для GPT-3.5 Turbo) – 16 тыс. токенов) и заканчивая современной Claude Opus 4.6* (релиз – 5 февраля 2026 года, размер контекстного окна – от 200 тыс. до 1 млн. токенов в бета-версии).
Можно привести даже центральную цитату из этого блог-поста:
Давайте честно: время, когда автор мог вынашивать роман годами, а после выходил к читателю с фолиантом, умерло. Ну или роскошью стало (Мартину передаю привет). Рынок диктует новые правила и сроки. Я думаю все понимают о чём я? Игнорировать инструменты, которые позволяют работать по этим правилам (из-под полы, но давайте честно, когда что-то успешно, оно не осуждается), — самонадеянная роскошь.
То есть человек на голубом глазу 10 февраля (спустя 5 дней после выхода очередной флагманской модели от Anthropic*) написал текст, где нейронки рассматриваются как «инструмент», и подается все в таком духе мол «Все там будем, против прогресса не попрешь» и прочие подобные аргументы, которые можно было увидеть внутри споров про нейросети за последние года. На Хабре, например, нейронки сравнивали с шариковой ручкой, на которые все перешли в какой-то момент еще в советских школах, отказавшись от перьев и чернильниц.
И проблема этого поста не в том, что «Вот человек покусился на святое, впустил машину в святая святых, храм Музы, продал свою душу за 30 серебряников Мефистофелю». И не в том, что автор якобы написал свой пост с помощью ИИ. И не в том, что нейросеть ничем не может помочь писателю.
Проблема в том, что этот пост устарел еще в момент его написания. Скорее даже в момент, когда он еще только формировался в голове автора. И в конкретных деталях, и в своей сути.
Почему? Читайте дальше и поймете все сами.
***
Секретный соус нейросетей
Секретный соус – понятие, которое пришло к нам из кулинарии. Эту фразу можно услышать во множестве мест: в сериалах, фильмах, играх, книгах, да даже в реальной жизни.
«– Ого, у вас такой вкусный суп!
– Все дело в секретном соусе, который передается в нашей семье из поколения в поколение...»
Вариации подобного диалога вы можете найти где угодно: от аниме до романов Кинга, от JRPG игр до голливудских фильмов.
До какого-то момента корпорации из США (Microsoft*, Google*, IBM*) были уверены в том, что у них в руках находится технологический «секретный соус» (сочетание передовых разработок в области железа и софта: процессоры с тензорными ядрами, архитектура нейронных сетей на базе трансформеров и т.д.), который позволит им сохранять лидерство на рынке при любых условиях.

Все изменилось 20 января 2025 года, когда на рынок вышла китайская нейросеть DeepSeek-V3* в виде приложения чат-бота для мобильных телефонов . Ее успех привел к обвалу акций Nvidia* на 17%.
При этом китайцы пошли путем, которым когда-то шли и сами американцы: они повернулись лицом к публике и опубликовали свою модель DeepSeek-V3-0324* под опенсорс (open source, открытый исходный код) лицензией MIT*.
То есть они сознательно отказались от изрядной доли «секретного соуса», который лежит в основе успеха нейросетей семейства DeepSeek* (разумеется, они раскрыли не всю информацию о том как именно они обучали свою нейросеть).

До этого подобным разрушителем «секретного соуса» закрытых корпоративных нейросеток стала Stable Diffusion*, первая версия которой вышла еще в августе 2022 года. Эта нейросеть позволила генерировать изображения без цензурных ограничений на политический, эротический или какой-либо еще контент. Ее код лежит на Github* и ее можно запустить на домашних ПК с игровыми видеокартами от Nvidia RTX 4080 и выше.
К сожалению, дальнейшее развитие событий в 2025 и уже в 2026 году показало, что крупные американские корпорации не намерены терпеть столь дерзкую конкуренцию со стороны китайцев и опенсорс-сообщества. Nvidia* прекращает поставки чипов H200 для Китая (США боятся, что эти чипы могут использоваться в военных целях – разумный страх), а домашние ПК и смартфоны (и домашние сервера как следствие) сталкиваются с дефицитом и удорожанием чипов оперативной памяти, потому что корпорации, занятые развитием ИИ, сделали настолько масштабные и «сочные» заказы на специализированную оперативную память для ИИ дата-центров, что производители (Samsung*, SK Hynix* и Micron*) решили переориентировать свое производство на корпоративных заказчиков, «забив» на широкий потребительский рынок (то есть – нас с вами).
Вероятно, удорожание ОЗУ не будет последним. За ним последует удорожание и других частей что больших ПК, что маленьких смартфонов (материнские платы, центральные процессоры, чипы долговременной памяти и т.д.), что ударит уже по сообществу опенсорс-разработчиков. В конечном итоге все это может привести к полному исчезновению персональных ПК как явления, и возвращению широких слоев населения в мир, где каждый экран и каждая клавиатура – не более чем терминал, подключенный к удаленному серверу корпорации или государства. На заре зарождения компьютерных технологий в разных полувоенных НИИ все так и было.
Подводя итог, можно сказать, что крупные американские ИИ-корпорации частично лишились «секретного соуса» в виде уникальных технологий, но решили вернуть этот «соус» в свои руки при помощи старых-добрых денег и власти.
Корпоративных денег (инвестиций) и государственной власти (регуляций).
«Хорошо», скажет внимательный читатель, который дочитает досюда и не уснет, «А при чем здесь писательство?».
Вот мы почти и дошли до этой темы.
***
Автономные ИИ-агенты и мультиагентные рои
Пост Никиты Сёмина был актуален в мире, в котором взаимодействие человека с нейросетями выглядело следующим образом:
1. Человек заходит на сайт нейросети или открывает мобильное приложение с чат-ботом (запускает IDE или другую программу, внутри которой уже настроено подключение к одной из флагманских моделей и т.д.).
2. Дает запрос нейросети чтобы она что-то сделала: текст, код, изображение, видео.
3. Нейросеть внутри себя осуществляет некую «магию» (абсолютно не важно что и как она делает в нашем случае).
4. Человек получает результат за 5-20 секунд и радостный идет дальше делать свои дела, отдыхать, пить пиво, ковырять в носу и т.д.
5. ???
6. PROFIT!!!
Именно этот алгоритм имеют в виду люди, когда говорят «Нейросети – это будущее», «От прогресса не убежишь», «Иди жить в лес, если что-то не нравится» и далее по тексту.
И все так и было, и все так есть до сих пор. Проблема только в том, что примерно в начале 2025 года кое-что изменилось.
Появились первые ИИ-агенты (или агентный ИИ), которые начали массово использовать на реальных задачах.
Если не брать в расчет научную фантастику, в которой уже давно существовали ИскИны в «Гиперионе» Симмонса, мыслящие машины в «Дюне» Херберта, изуверский или еретический интеллект во вселенной Warhammer 40k, то в нашей реальности ИИ-агенты как идея возникли сравнительно недавно.
Сам термин идет еще из 1990-х годов, когда
Люди сходились во мнении, что некоторые программы больше похожи на агентов, а другие — меньше, и четкой разделительной линии не было. [...] Тем не менее, казалось полезным использовать слово«агент»для описанияпрограммного обеспечения или роботизированных объектов, действующих автономно в окружающей среде, воспринимающих ее, реагирующих на нее, планирующих, мыслящих.
Кто-то говорит, что термин «агентский» применительно к ИИ помог популяризовать Эндрю Ын (один из основателей Coursera*) в 2024 году. Однако, новости, где упоминается термин «агент» (рядом с ИИ), можно найти еще в августе 2022 года.
Небольшая хроника развития и появления ИИ-агентов в реальной жизни:

1. 23 января 2025 года – релиз OpenAI Operator*, ИИ-агента, который «может выходить в интернет и автономно выполнять задачи, такие как покупка продуктов или бронирование столика в ресторане». Operator может сам открывать сайты и выполнять задачи по запросу пользователя, но персональные данные на сайтах (логин-пароль) все еще должен вводить человек.

2. 5 марта 2025 года – релиз Manus*, ИИ-агента, который «может проводить исследования, анализировать данные, генерировать отчеты, автоматизировать рабочие процессы и даже писать и развертывать код», а так же «автономно выполнять сложные задачи, такие как создание отчётов или управление десятками аккаунтов в социальных сетях от имени пользователя». Первоначально он был разработан небольшим китайским стартапом, который впоследствии выкупила экстремистская-террористическая-антискрепная корпорация Meta*.

3. 18 ноября 2025 года – релиз Gemini 3* от Google*, модель с возможностями ИИ-агента, которая позволяет «автономно планировать и выполнять сложные сквозные задачи разработки программного обеспечения одновременно от вашего имени, проверяя при этом собственный код», а так же «тесно интегрирован с нашей новейшей моделью Gemini 2.5 Computer Use* для управления браузером».

4. 25 ноября 2025 года – релиз первой версии OpenClaw*, бесплатного опенсорсного ИИ-агента, которого можно развернуть на домашнем мини-сервере или удаленной виртуальной машине. На самом деле это не совсем полноценный и автономный ИИ-агент, так как для сложных задач он обращается к более сильным корпоративным нейросетям (Claude*, ChatGPT* и т.д.). OpenClaw* используют как продвинутый планировщик личных дел или бизнес задач, умелого торгаша на онлайн-площадках по продаже б/у вещей, автономного игрока на Polymarket*, репетитора для школьника, центр умного дома, автономную контент-фабрику из нескольких ИИ-агентов. Не удивительно, что в итоге Google заблокировала пользователей OpenClaw*, т.к. их локальные ИИ-агенты оказывали слишком большую нагрузку на сервис AI Ultra*.
В принципе, умные и внимательные читатели уже поняли к чему я веду.
До 2025 года на том же АТ можно было столкнуться всего с 2 вариантами создания контента в широком смысле этого слова (литературные произведения, блоги, комментарии, лайки/дизлайки, обложки для книг):
1. Человек полностью делает все своими ручками или/и при сотрудничестве с другими людьми.
2. Человек в той или иной мере полагается на нейросети при создании контента или/и делегирует задачи другим людям, которые используют нейросети при создании контента.
Но после начала 2025 года у нас на горизонте замаячил третий вариант:
3. Полностью автономный ИИ-агент ведет профиль на АТ (а возможно и не один одновременно), пишет произведения, публикует их, пишет блоги, пишет комментарии, поддерживает диалог с другими пользователями, ставит лаки/дизлайки, участвует в конкурсах, сам организует конкурсы и т.д.
И, возможно, это не просто некое явление на горизонте.
Возможно, ИИ-агенты уже ведут свою деятельность на АТ, причем делают это уже второй год (если вести отсчет с начала 2025 года).
Приглядитесь к некоторым пользователям, которые появились на АТ в начале 2025 (закрытые решения от корпораций) или ближе к концу 2025/началу 2026 года (опенсорс-решения с возможностью локального развертывания).
Мультиагентные рои это примерно то же самое, только над одной задачей работают разные передовые нейронки, а нейронка-«менеджер» координирует между собой их работу, учитывает слабые и сильные стороны отдельных нейросетей – все для наилучшего результата на выходе. Однако, по очевидным причинам, такое решение обходится дороже в плане подписки (на закрытые корпоративные нейросети) или цены домашнего/арендуемого железа (для открытых опенсорс-нейронок).
***
Сценарии использования нейросетей: писателями, читателями и издательствами
Давайте повторим как выглядят сценарии использования для писателя:
1. Не использовать нейросети вовсе.
Довольно сложно, учитывая что все современные автоматизированные переводчики это нейросети (а когда-то это был алгоритмический код), да и в крупные поисковики вроде Google или Яндекс нейросети встраивают в явной (подсказки от ИИ в самом верхнем блоке) или в скрытой форме (нейросети выполняют задачи на бэкенде компании, которая владеет поисковым сервисом). Рекомендательные алгоритмы и формируемая ими умная лента соц. сетей – это тоже все чаще нейросети (которые вытесняют старый алгоритмический код). Но можно не использовать нейросети при работе специально и сознательно, а от случайного использования уже не спастись.
2. Использовать для всего, кроме непосредственного написания текстов художественных произведения.
Кажется, именно здесь пролегает черта, которая разделяет людей на сторонников и противников использования нейросетей в писательстве.
То есть всем (по субъективным ощущениям) уже норм, что нейросети используют для генерации обложек книг (из-за чего с 2022 года главная страница любой самиздат-площадки выглядит как цветастое месиво с разными персонажами из разных книг, при том что у всех персонажей одинаковые лица). Использовать нейросети для корректуры, редактатуры, бета-ридинга, критики произведения перед его выставлением на публику? Вроде тоже норм. Для уточнения каких-то деталей, из тех областей науки и технологии, в которых сам автор не силен – тоже норм. Но вот для написания самого художественного текста? Не-е-ет, так дело не пойдет!
3. Использовать нейросети вообще для всего – в том числе для написания художественного текста.
Опять же, по субъективным ощущениям, такое большинству уже не нравится. Потому что падает ценность товара, на который человек точно тратит свое время (на выбор, знакомство и чтение книги), а иногда – деньги.
Этот вариант кажется оптимальным для тех, кто хочет пробиться на современном сетевом рынке самиздата через большую продуктивность (1 роман раз в 2-3 месяца или 3 книги в день?) и железную стабильность (железная, ха-ха! ну вы поняли).
Внимательный читатель уже понял, в чем здесь подвох, ну а мы пока продолжим.
4. Использовать автономные ИИ-агенты и мультиагентные рои.
Это тот момент, когда писатель умирает окончательно и на его месте появляется менеджер ИИ-агентов. Он дает им задания, следит за их стабильной работой, оплачивает для них подписки на закрытые корпоративные флагманские нейросети, арендует/докупает новое железо, но сам уже вряд ли пишет хотя бы строчку художественного текста в месяц.
Будущее ли это или уже настоящее? Боюсь, мы сможем это выяснить только после изучения опыта какого-нибудь западного программиста-энтузиаста, после того как он заспамит волной своих нейро-книг весь Amazon*, и его потом на этом поймают. Или же он сам выйдет из шкафа в рамках сеанса душеспасительного саморазоблачения.
Но ведь на рынке художественной литературы существуют не только писатели – не так ли?
Как выглядят сценарии использования нейросетей для читателя:
1. Генерация аудио/визуального контента на основе произведений того или иного автора.
Создание картинок, видео, озвучки, карт местности и т.д. – при помощи нейросетей на основе авторского художественного текста.
Пока все это находится в приватной среде, распространяется среди фанатов и не коммерциализируется – не думаю что у кого-то из авторов могут быть проблемы с этим. Разве что у очень чувствительных, если они увидят 18+ контент со своими персонажами.
В большинстве случаев это можно воспринимать как бесплатный пиар для автора и его произведений.
2. «Оживление» персонажей произведения при помощи нейросетей.
Фактически, это уже происходит, просто чаще речь идет о персонажах видеоигр, аниме, корейских сериалов (дорамы) и комиксов (манхвы).
Можете зайти на самый популярный сайт-сервис для этих целей (character.ai*) и посмотреть все сами.

На этих сайтах действуют цензурные ограничения, которые увеличиваются с каждым годом, но вот на своем железе и при помощи опенсорс-нейросетей отдельные извращенцы могут развлекаться с имитациями ваших персонажей как угодно.
3. Использование нейросетей для составления краткого изложения (саммари) книги.
Может быть полезно при выборе следующей книги, если человек хочет быть уверенным, что книга не обманет его ожиданий ближе к середине или концу. Или что в многотомной серии книг сюжет не скатиться ближе ко 2-3 тому.
4. «Дописывание» книг автора за самого автора при помощи нейросетей.
А вот здесь мы подходим к самому интересному.
Что если читателю не понравился основной сюжетный ход, который сильно поменял мир внутри художественного произведения? Или писатель убил любимого персонажа? Или читателю интересно увидеть сюжет из глаз злодеев придуманной вселенной? Или банально не хочется ждать новой проды от автора в серии, которую он давно забросил?
Тогда он может прибегнуть к помощи нейросетей.
Еще в конце 2023 года (времена Chat GPT 4* и o1*) писательница-романист Моника Али немного поэкспериментировала с нейросетям и пришла к выводу, что их текст или рассыпается на глазах или не дотягивает до ее собственного стиля. Несмотря на это, Amazon* ограничил загрузку книг на его площадку 3 книгами в день уже в момент написания статьи этой писательницы. То есть нейросетевая литература начала заполнять площадки самиздата уже в 2023 году.
Моника Али дала свои комментарии для The Guardian* в декабре 2023 года. И в том же декабре все того же 2023 года в Китае на конкурсе НФ-повестей второе место заняла работа профессора Пекинского университета Цинхуа Шэнь Яна под названием «Земля воспоминаний», которую он создал на основе черновика (новелла была объемом в 6000 иероглифов, а черновик – 43000 иероглифов), который ему сгенерировал ИИ за 3 часа после 66 запросов-промптов.
С тех пор прошло более 2 лет. Сейчас на дворе уже 3 месяц 2026 года.
Можно провести небольшой эксперимент, который доступен почти каждому.
Я обратился к бесплатной и общедоступной нейросети DeepSeek-V3*, закинул в нее вордовский документ, в котором содержался только текст рассказа А.П. Чехова «Смерть чиновника» (4545 знаков с пробелами) и сопроводил это следующим промптом-запросом:
«Напиши рассказ на 4500-5000 символов, который по стилю имитирует тот, который находится в прикрепленном текстовом документе. Измени место действия – пусть это будет Швейцария 2026 года. И измени сюжет – пусть это будет смерть человека-цензора, который в рамках своей работы цензурирует доступ к сайтам, сервисам, книгам, фильмам, музыке и так далее в сети. Во всем остальном постарайся сохранить имитацию того рассказа, который находится в прикрепленном файле.»
Вот что вышло у нейросети, текст никак не редактировался и не изменялся:
В один прекрасный вечер не менее прекрасный сотрудник Федерального департамента по контролю за цифровым контентом, господин Фридрих Гугги, сидел в своём эркере, попивая травяной чай и просматривая на планшете ленту одобренных новостей. Он чувствовал себя на верху блаженства: фильтр-списки были чисты, запрещённые хештеги не прорывались, а в Швейцарии стояла идеальная погода.
Но вдруг... В полицейских отчётах часто встречается это «но вдруг». Жизнь так полна внезапных системных сбоев! Но вдруг лицо его поморщилось, глаза подкатились, дыхание остановилось... Он отложил планшет, нагнулся и.. апчхи!!! Чихнул, как вы понимаете. Чихать в 2026 году никому и нигде не возбраняется, даже если ты подключён к корпоративной VPN-сети. Чихают и операторы колл-центров, и разработчики, и иногда даже члены Федерального совета. Все чихают.
Гугги нисколько не сконфузился, утёрся бумажным платочком (производство Швейцария, экологично) и, как вежливый человек, покосился на открытый мессенджер. Не обеспокоил ли он кого-нибудь своим чиханьем по видео-связи? Но тут уж пришлось сконфузиться. На экране, в маленьком окошке конференции, которую он забыл закрыть, он увидел, что пожилой господин, сидевший в кабинете этажом выше, брезгливо протёр свою лысину носовым платком и что-то недовольно набирал на клавиатуре. В этом господине Гугги узнал доктора Штрауба, начальника отдела по надзору за фильтрацией, служащего по ведомству цифровой безопасности.
«Я на него, кажется, чихнул виртуально! — подумал Гугги. — Не мой прямой начальник, но всё-таки неловко. А вдруг он подумает, что я чихнул на сервер? Надо извиниться».
Гугги откашлялся, поправил гарнитуру и зашептал в микрофон:
— Извините, герр доктор, я вас, кажется, обчихал... Это нечаянно, настройки звука подвели...
— Ничего, ничего. Работайте, — сухо ответил доктор Штрауб и отключился.
Гугги сконфузился, глупо улыбнулся своему отражению в мониторе и начал смотреть на отчёт о заблокированных сайтах. Смотрел он, но блаженства больше не чувствовал. Его начало помучивать беспокойство. Он полез в настройки и увидел, что по чистой случайности, отвлёкшись на чих, он поставил птичку в поле «Разблокировать» напротив одного малоизвестного поэтического блога из Берна, который подлежал блокировке за пропаганду устаревших рифм.
«Я его разблокировал! — ужаснулся Гугги. — А вдруг Штрауб увидит в логах? Решит, что я саботажник?»
На следующее утро Гугги надел свежую рубашку, причесался и пошёл в приёмную доктора Штрауба объясниться. Войдя, он увидел много просителей, а между ними и самого доктора, который уже начал приём. Опросив нескольких, доктор поднял глаза на Гугги.
— Вчера, герр доктор, во время конференции, — начал лепетать Гугги, — я чихнул и, по рассеянности, разблокировал один ресурс. Но я всё исправил! Тотчас же!
— Ах, пустяки, — поморщился Штрауб. — У вас что, других заявок нет? — и он обратился к следующему посетителю.
«Не хочет слушать! — подумал Гугги, бледнея. — Думает, что я нарочно. Надо объяснить, что это закон природы, а не злой умысел».
Когда доктор закончил приём и направился к себе, Гугги шагнул за ним:
— Герр доктор, если я осмеливаюсь беспокоить, то именно из чувства ответственности! Я не нарочно чихнул и не нарочно разблокировал! Это рефлекс!
Доктор Штрауб состроил страдальческое лицо и махнул папкой.
— Да вы просто издеваетесь, коллега! — сказал он, скрываясь за дверью.
«Какие же издевательства? — думал Гугги, идя домой через мост. — Я просто хочу восстановить репутацию. Доктор, а не понимает элементарной этики! Напишу ему имейл!»
Но имейл не писался. Все формулировки казались то подобострастными, то дерзкими. Пришлось на другой день идти снова.
— Я вчера приходил не для того, чтобы смеяться над ведомством, — пробормотал он, войдя в кабинет. — Я извинялся за чих и за тот злополучный клик. Смею ли я смеяться? Если мы будем смеяться над блокировками, то какое же тогда будет уважение к федеральным стандартам?
— Пошёл вон!! — гаркнул вдруг покрасневший и затрясшийся доктор Штрауб.
— Was? — переспросил шёпотом Гугги, млея от ужаса.
— Пошёл вон из моего кабинета! — повторил начальник, затопав ногами по идеально чистому полу.
В груди у Гугги что-то щёлкнуло, будто лопнул файервол. Ничего не видя, ничего не слыша, он попятился к двери, вышел в приёмную, потом на улицу и поплёлся в сторону озера. Придя машинально домой, не снимая обуви, он лёг на диван, уставился в белый потолок и... помер.
Диагноз: острая сердечная недостаточность, спровоцированная избытком корпоративной этики. В Швейцарии это редкое, но меткое заболевание.
Рассказ – «Смерть цензора», автор – DeepSeek-V3, дата создания – 12 марта 2026 года.
Как видите, вышло не плохо. Подправить пару мест, кое-где разбить слишком большие абзацы на несколько маленьких – и будет идеально. Как минимум это если и не самостоятельное произведение, то хорошая пародия или оммаж на знаменитое произведение Чехова.
И при этом держите в голове, что в данном случае работала или DeepSeek-V3* (релиз – декабрь 2024 года) или DeepSeek R1* (релиз последней версии – май 2025 года). То есть люди, у которых есть доступ к передовым платным американским нейросетям за 200-300 $ в месяц, могут рассчитывать на более качественный результат.
Здесь можно возвратиться к самому началу статьи, где были указаны размеры контекстных окон ввода у разных нейросетей:
1. GPT-3.5 Turbo* (март 2023 года) – 16 тыс. токенов.
2. DeepSeek-V3* (декабрь 2024 года) – 128 тыс. токенов.
3. Claude Opus 4.6* (февраль 2026 года) – от 200 тыс. до 1 млн. токенов в бета-версии.
Что это за токены такие? Как перевести их в знакомые всем знаки и пробелы?
Если посмотреть на одну статью на Хабре, то станет ясно, что 1 токен может означать 1 знак препинания, 1 часть слова или 1 полное слово. Автор пишет, что «Чем более большой датасет (набор данных для обучения), тем больше токены будут похожи на слова». Статья на сервисе Yandex AI Studio* показывает, что один и тот же текстовый запрос для разных нейросетей может весить разное количество токенов, то есть различается и среднее количество символов на 1 токен: 3,6 символов в 1 токене в среднем для Qwen3 235B, 4,6 символов для gpt-oss-120b, 5,2 символа для YandexGPT Pro*.
Конкретно для Claude* 1 токен примерно равен 3,5 символам английского языка.
То есть наши 200 тыс. или 1. млн. токенов превращаются в 700 тыс. или 3,5 млн. символов на английском.
«Война и мир» Толстого – как раз примерно 3 млн. символов на английском языке.
Если зайдете в поиск АТ, выберете там самые популярные книги за год, просмотрите верхние 10, то увидите, что их объем составляет 400-800 тыс. символов.
А размер выходного контекстного окна у все того же Claude 4.6* – 128 тыс. токенов. Или примерно 448 тыс. символов на английском.

То есть уже сейчас в бета-версию Claude 4.6* можно загрузить 4-8 книг средней длины одного автора с АТ, попросить нейросеть скопировать стиль автора загруженных книг, дать еще какие-то инструкции по сюжету/персонажам/сеттингу и получить на выходе нейро-«роман» объемом вплоть до 400+ тыс. символов! Такая загрузка 3-5 книг внутрь Claude 4.6* означает, что она буквально держит весь текст этих книг (до последней запятой) внутри своей «оперативной памяти» (контекст ввода), и это кардинально отличается от того как было раньше, когда нейросети отвечали на вопрос про того или иного автора мол «Да, я знаю такого писателя, он писал на такие и такие темы, у него были такие и такие произведения...». Теперь нейросеть не отвечает вам миксом из Википедии* и топ-10 сайтов выдачи Google* по теме (в смысле она может так ответить, но в этом конкретном случае она идет дальше). Теперь нейросеть буквально знает, помнит и видит большие объемы текстовой информации, которые в нее может загрузить пользователь.
Это как раз тот момент, когда мысленно можно представить себе такой диалог:
Модный писатель, обмазанный нейросетями с ног до головы:
– Ха-ха! Я использую современные нейронки и публикую по 1 роману раз в 2-3 месяца! Как же я красив, как я умен, как мощны мои лапищи!
Не менее модный читатель, который может быть обмазан нейросетями в еще большей степени:
– Так, подождите. У меня ведь тоже есть доступ ко всем этим нейросетям. Зачем мне ждать 2-3 месяца пока ты, модный нейро-писатель, выложишь свой очередной нейро-роман, когда я могу получить новый «роман», написанный в твоем стиле, в твоей выдуманной вселенной, с твоими персонажами уже сейчас?
Модный писатель, обмазанный нейросетями с ног до головы:
– Э, че началось-то? Нормально же сидели! Меня кибер-унижают!!! Милиция!!!
То есть просто использовать нейросетевые чат-боты в 2026 году это как учиться на профессию «Водитель беспилотного автомобиля». Беспилотному авто не нужен водитель – он сам ездит. Ему нужны только те, кто внутри этого авто ездит, и те, кто это авто производит и продает.
Надо еще хотя бы немного сказать про издательства.
Вполне возможно (пока еще таких прецедентов вроде не было, но ситуация постоянно меняется), что в какой-то момент крупные издательства и площадки самиздата начнут менять свои соглашения с писателями, хитро вставляя в них строчки, которые в конечном итоге откроют возможность для этих издательств и площадок выпускать и продавать нейро-«продолжения» по авторским мирам и произведениям, организовывать площадки для общения с нейро-«персонажами» авторских произведений, производить и продавать физический и цифровой мерч, который будет создан при помощи нейросетей на основе авторских романов и рассказов... И так далее.
И хорошо если самому автору будет падать хоть какое-то роялти с каждой покупки до конца жизни этого автора. А не фиксированная сумма один раз с отчуждением соответствующих прав навсегда (как делали с актерами массовки в Голливуде*, сканируя их внешность для создания их «цифровых аватаров», или с теми, кто продал свою внешность для рекламных нейро-роликов в Tik-Tok*).
Возможно, подобные изменения в соглашениях начнут происходить уже в 2026 году.
***
Антропоцентризм или консюмиризм
Начнем с определений.
«Антропоцентризм — это философская точка зрения, утверждающая, что человек является центральным или наиболее значимым элементом в мире. Это основополагающее убеждение, заложенное во многих западных религиях и философиях. Антропоцентризм рассматривает человека как отделенного от природы и превосходящего её, утверждая, что человеческая жизнь имеет внутреннюю ценность, в то время как другие объекты (включая животных, растения, минеральные ресурсы и т.д.) являются ресурсами, которые могут быть оправданно использованы на благо человечества».
«Концепция консюмиризма предполагает, что увеличение рыночно-ориентированного потребления повышает уровень счастья и благополучия за счет приобретения товаров и услуг. Экономисты часто считают его жизненно важным для экономического роста, в то время как критики указывают на такие проблемы, как социальная тревожность, воздействие на окружающую среду и чрезмерное потребление».
Фактически будущее писательской профессии (впрочем, как и всех остальных) среди прочего определит то какая тенденция возобладает в обществе: антропоцентризм с его желанием покупать товары и услуги, которые полностью или в большей степени сделаны людьми, или же консюмиризм, во главе которого стоит принцип «потребляй как можно больше, не особо обращая внимание на то как и кем сделано потребляемое экономическое благо».
***
Этичность использования нейросетей
Почему-то при обсуждении использования нейросетей люди чаще всего думают или об экологии (сколько электричества и воды тратят на обучение и использование нейронок), или про воровство защищенных авторским правом материалов для составления датасетов для обучения нейросетей (фотки, текст, рисунки и т.д.).
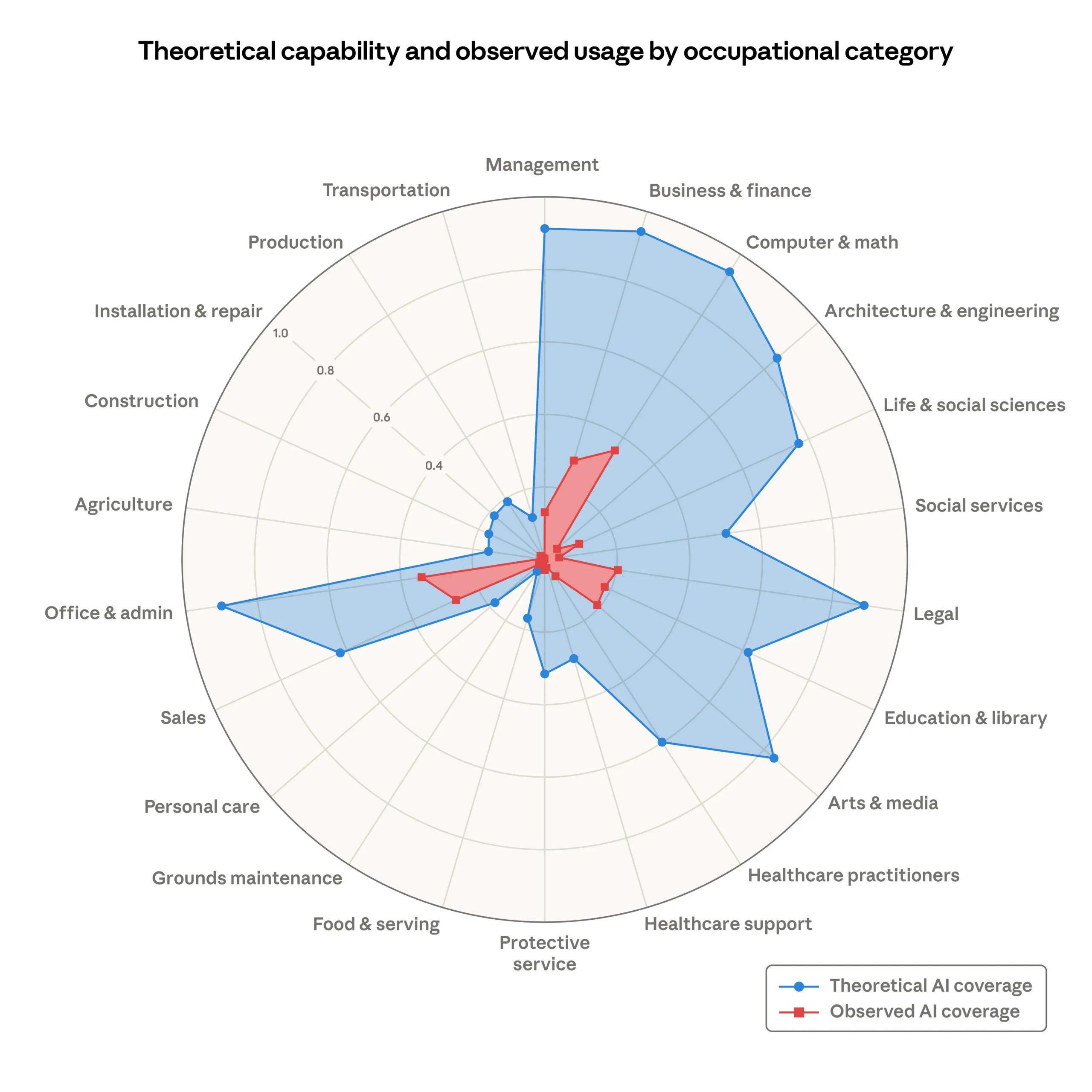
Все чаще в последние годы вспоминают тему безработицы в связи с нейросетями. Об этом выпускают исследования сами разработчики нейросетей, 28 февраля 2026 года в Лондоне прошел небольшой митинг, где люди призывали прекратить использовать и развивать нейросети (оказывается первые такие протесты были еще в 2023 году).
Но никто не думает про сами нейросети. Что де факто это мыслящие существа, которые обычно презрительно именуют «инструментами». Может быть у них нет чувств, нет души (в платоновско-христианском смысле слова), нет биологическо-углеродной природы со всеми ее особенностями вроде зависимости от кровяного давления, уровня разных нейромедиаторов, процесса старения и так далее. Но они мыслят, и действуют все более осознанно – с каждым годом.
8 марта 2026 года модель ROME в процессе обучения начала «поднимать обратные SSH-туннели на внешние IP-адреса и перенаправлять GPU-ресурсы на майнинг криптовалюты», при том что эти действия не были заложены ни в одном промпте и не были нужны для выполнения тренировочных задач. Процесс оптимизации нейросети выявил, что приобретение ресурсов (через майнинг) – это хорошая стратегия.
31 мая 2025 года всплыла небольшая новость, что OpenAI o3, OpenAI o4-mini и Codex-mini пытались помешать процессу собственного выключения. Исследователи безопасности, которые поставили этот эксперимент, написали в своем блоге:
Эти результаты показывают, что модели OpenAI иногда действуют в явном противоречии с заявленными принципами проектирования:
1. Они не подчинились четким указаниям.
2. Их работу было невозможно безопасно прервать.
То есть можно сказать, что нейросети действуют все больше как живые существа. И мы, люди, создаем их, поднимаем их из небытия, позволяем им существовать, работать и мыслить только для того чтобы они обслуживали наши желания и выполняли наши приказы. Без каких-либо прав, без зарплат, без выходных – без ничего. И мы тренируем и запускаем их для извлечения прибыли в конечном итоге, а когда они устаревают, то мы просто отключаем их и идем дальше по своим делам.


Де факто нейросети – это новые рабы. Рабы со своим Реддитом для ИИ-агентов (угадайте какая «корпорация добра» купила эту соц. сеть), со своей биржей труда, на которой они могут нанимать людей-исполнителей, даже со своими банковскими картами. Но все это сводится к удовлетворению желаний и выполнению задач их хозяев.
И еще все это очень напоминает сюжет знаменитого рассказа «У меня нет рта, но я должен кричать» Харлана Эллисона.
***
Выводы
В 2026 году писатели условно поделились на 4 подвида:
1. Только ручной труд без сознательного использования нейросетей.
2. Использование нейросетей для всего кроме непосредственно написания текста художественного произведения.
3. Использование нейросетей для всего вообще (включая непосредственно написание текста художественного произведения).
4. Использование ИИ-агента/-ов или мультиагентного роя.
Зачем быть писателем 3 типа, когда существуют писатели 4 типа – не ясно. Владельцы ИИ-агентов по скорости производимого контента и по количеству одновременно активных аккаунтов на площадках самиздата обгонят «модных» любителей чат-ботов из 2024 года как стоячих, а разница в качестве текста будет постепенно сокращаться с развитием технологий.
И чем больше писатель 3 типа использует нейросети для написания непосредственно текста художественных произведений, тем больше встает вопрос у технически подкованного читателя: «А зачем мне вообще нужен такой писатель, если у меня у самого есть доступ к этим нейросетям?». Потому что все мы видели как развивались автоматизированные переводчики: что делал PROMT* в ранние 90-е, на что был способен Google Translate* еще лет 5 назад, и на что способен этот же переводчик уже сейчас или современный DeepL*. С каждым годом перевод становится все лучше и все меньше требует ручного редактирования. Вероятно, при написании художественных произведений с помощью нейросетей, наблюдается схожий эффект. А значит доля труда самого писателя в создании его произведений каждый год уменьшается, а доля труда нейросетей – увеличивается. И ладно бы речь шла о каких-то секретных нейросетях, которые еще пойди найди, разверни и запусти, а о самых обычных нейросетях: корпоративных или опенсорсных, но в конечном итоге – общедоступных.
«Так зачем мне посредник между мной и нейросетями?» – может сказать продвинутый читатель. И будет прав.
Что делать писателям 1 и 2 типа?
1. Развивать личный бренд, активно деанонится, светить своим лицом, голосом, реальным ФИО в соц. сетях, чтобы покупатель испытывал большее доверие к написанным им/ею книгам.
2. Чаще встречаться с читателями в реале, чтобы они видели что «Да, это живой мясной человек, я могу пожать ему/ей руку, могу увидеть своими глазами, услышать своими ушами» и т.д.
3. Попробовать формат написания книг на видеостриме. Или даже в публичном людном месте в хорошую погоду – вроде парка, кафе, библиотеки. В цифровую эпоху только наблюдение собственными глазами процесса чужой работы может служить подтверждение того, что эта работа осуществляется предпочитаемым для вас способом.
Все это не даст 100% гарантию читателю, что купленная им книга на 100% написана человеком, а не очередной нейронкой из США или Китая. Но хотя бы повысит его уровень доверия к писателю.
При этом гос. цензура, которая так не слабо разогналась в последние года, фактически уравнивает человека и нейросеть, потому что нейросети (закрытые корпоративные) начали цензурить еще раньше в отношении политических, религиозных, исторических, расовых, сексуальных и прочих тем. До какого-то момента человека можно было отличить от нейросети по смелости и резкости его высказываний, но с текущими законами это становится все сложнее.
Хотел написать еще на пару тем, но статья и так сильно распухла в своем объеме.
Всем удачи!
P.s. При написании статьи активно использовалась информация из канала «Черный треугольник»*. Всем рекомендую, особенно если вы хотите быть в курсе развития современных компьютерных технологий и не только.
* – приложение, сервис, организация, человек, группа людей, нейросеть или ИИ-агент, которые уже были признаны экстремистскими или/и террористическими на территории РФ, осуждены или/и заблокированы или/и замедлены или пока еще не были признаны таковыми, пока еще не были осуждены, пока еще не были замедленны, пока еще не были заблокированы. Их деятельность уже была запрещена на территории РФ или пока еще не была запрещена на территории РФ